| John W Regular  Posts: 96 Joined: 6/18/2011 Location: Sydney, NSW, Australia 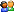 User Profile User Profile | Here's a second GA improvement suggestion. I ran an experiment where I kept the rules as generated, and then deleted and renewed the data samples as the GA progressed its iterations. Each red triangle in the graph indicates a data sample change. The starting data sample ceased generating meaningful additional rules at n=5000 I changed the data sample at n=10,000 and that data set stopped generating much after n=18,000. I changed again at n=75,000 and had some very quick rule formation for about 1000 iterations. I changed the data set again at 80,000 and that has just kept on generating rules. Based on the graph above there are data sets that are way better (or way worse) for rule generation. If the GA can find and use the better data sets then that should enhance GA rule generation and GA fitness. Suggestion - instead of importing one data set could the GA import 'n' data sets at its formation. Allow the GA to gravitate over time to samples from those data sets that generate more rules. This could be as simple or as complex as Nirvana wish, but a simple method would be if the data set ceases to train meaningful rules after 'x' iterations then switch to the next data set. [Edited by John W on 2/28/2020 4:16 PM]  Attached file : TrainNewData.png (26KB - 730 downloads) Attached file : TrainNewData.png (26KB - 730 downloads) | |